An Affinity Based Greedy Approach towards Chunking for Indian Languages Dipanjan Das, Monojit Choudhury, Sudeshna Sarkar and Anupam Basu
Department of Computer Science and Engineering
Indian Institute of Technology, Kharagpur
email: [email protected], {monojit, sudeshna, anupam}@cse.iitkgp.ernet.inAbstract
Abney (1991) viewed chunks to be connected sub-graphs of the parse tree of a sentence. For example,
The young girl was sitting on a bench.
language text. Chunking for Indian lan-guages require a novel approach because
of the relatively unrestricted order ofwords within a word group. A compu-
[The young girl]/NP [was sitting]/VP [on a
on valency theory and feature structures
where NP, VP and PP are noun, verb and preposi-
draws an analogy of chunk formationin free word order languages with the
Several methods for chunking have been explored
for English and other European languages since
the 90’s. (Abney, 1991) introduced a context-free
unavailability of large annotated corpora
grammar based approach for chunking of English
forces one to adopt a statistical approach
focussed on statistical techniques. Machine learning
based approaches eliminate the need of manual rule
creation and is language independent. (Ramshaw
and Marcus, 1995) proposed a transformation
based learning paradigm for text chunking, whichachieved approximately 92% precision and recallrates. This work involved text corpora as training
Introduction
examples where the chunks were marked manually. Other works report more than 90% accuracy in
Chunking or local word grouping is an intermedi-
identifying English noun, verb, prepositional, ad-
ate step towards parsing and follows part of speech
jective and adverbial phrases (Buccholz et al, 1999;
tagging of raw text. Other than simplifying the pro-
Zhang et al, 2002). The work of (Vilain and Day,
cess of full parsing, chunking has a number of appli-
2000) in identifying chunks is worth mentioning
cations in problems like speech processing and in-
here because their system used transformation based
formation retrieval. Chunking has been traditionally
rules which would either be hand-crafted or trained.
defined as the process of forming groups of words
The trained system performed with precision and
based on local information (Bharati et al, 1995).
recall rates of 89% and 83% respectively, whereas
they attained much lower precision and recall rates
this description may have a nested structure as well.
in the hand-engineered system, and hence their
The following sentence elucidates some chunks for
observations justified the use of the learning based
and context sensitive rules for part of speech tag
sequences to chunk sentences. The rules in their
work were also derived from training data.
wood[of] table[on] very beautiful flower-vase was
The problem of chunking for Indian languages
(There was a very beautiful flower-vase on
takes a new dimension for a two reasons.
for most free-word order languages, the internalstructure of the chunks often have an unrestrictedorder, for which chunk identification becomes a
In sentence 3, kAThera TebilaTira upara forms a
challenging task in comparison to English text.
noun chunk (NN) which has two chunks within it -
However, full parsing of free-word order languages,
a noun chunk and a postposition (PPI). In the noun
which is a hard task, becomes much easier to solve
chunk khuba sundara phuladAni, there is an adjecti-
when the intermediate step of identifying chunks
val chunk (JJ) khuba sundara and a noun phuladAni
is achieved. Second, there is a dearth of annotated
nested inside. It should be noted that due to lack
of strong word ordering constraints in Bengali, the
number of sentences used for training an NLP
chunks can be freely permuted in the above sentence
system for languages such as English goes beyond
to yield grammatically correct sentences having the
a few millions. In the scenario of Indian languages,
same meaning. However, words may not be per-
such colossal amount of training data is hardly
muted across the chunks. For example, the sentence
sundara TebilaTira upara khuba kATheraphuladAni Chila. beautiful table[of] very wood[of] flower-
An approach towards chunking based on valencytheory and feature structure unification has been
described here. An analogy of unification of FSs of
syntactic units has been drawn with the formationof complex structures from atoms and radicals. Inthe formalism reported the parse tree of a sentence
has further been imagined to be similar to the
syntax, but a different semantics. Thus informally,
molecular structure of a substance. A chunker for
a chunk or a word group is a string of words inside
Bengali has been implemented using this formalism
which no other word of the sentence can enter
with a precision of around 96% and a recall of
without changing the meaning of the sentence. The
approximately 98%. In the next section we describe
present paper assumes this definition to identify
the nature of chunk formation in Bengali.
chunks for a particular input sentence.
The problem of dividing a Hindi sentence into
Chunking in Free Word Order
word groups has been explored by (Bharati et al,
Languages
1995). The output of the grouper served as an inputto a computational Paninian parser. However, in
In this paper, chunking, especially with a view to-
their work, they made a distinction between local
wards free word order languages, is defined to be the
word groups and phrases. They assert from a com-
process of identifying phrases in a sentence that have
putational point that the recognition of noun phrases
an internal arrangement independent of the over-
1In this paper, Bengali script has been written in italicized
all structure of the sentence. Chunks according to
Roman fonts following the ITRANS notation.
and verb phrases is neither simple nor efficient. Therefore, the scope of the grouper was limitedand much of the disambiguation task was left tothe parser.
in Hindi has been explored by (Ray et al, 2003)using a rewrite rule based approach.
technique gave only one possible grouping of aparticular sentence, did not consider sentence levelconstraints, which at times generated ill-formedgroups and the case of noun-noun groups has beencompletely ignored. Formalism Overview of the Framework
The present paper focuses on a formalism devel-oped using an analogy with formation of bonds in
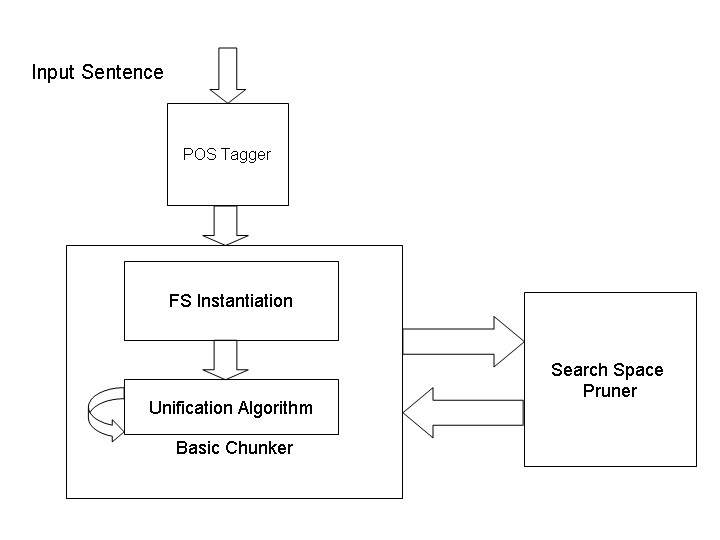
Figure 1 shows the framework proposed in this
chemical compounds. The criteria that governs the
work. The main components of the system are the
series of bond formations is the minimization of
POS tagger, the chunking system and a search space
energy through which a stable state is reached. Two
atomic units can form a bond if and only if they
and tags each word with its POS category and other
have a mutual attraction towards each other, which
morphological attributes valid for that category.
is governed by the property called valency.During
The grouper tries to formulate valid groups based
bond formation of two structures, there is an amount
on the POS tags and the morphological attributes
of energy that is released and this brings the system
as provided by the tagger. The first phase of the
to a more stable state. Ultimately, when the system
grouping is the feature structure instantiation of
cannot release any more energy, the final structure
each and every word of the sentence followed by
the grouping algorithm. At each step of grouping,a search space pruner reduces the number ofredundant groups that may have been formed by the
We can extend this concept to chunking (or pars-
chunking system. The current work focusses only
ing in general) as follows: The individual words of
a sentence are the atoms, which have valencies rep-resentative of their syntactic and/or semantic prop-erties. The chunks can be viewed as semi-stable
Valency and Feature Structures
molecular complexes formed out of a set of atoms,which in turn have its own valencies. A quantity
Valency theory takes an approach towards an
called the bond energy reflects the relative affinity
analysis of sentences that focuses on the role of
between two syntactic units. The higher the bond
energy between two units, the higher is the prob-
certain verbs allow only certain kinds of predicates
ability that they will form a chunk. The complete
some of which are compulsory while some others
parse-tree of the sentence is analogous to the final
may be optional. The arguments that a verb can
chemical compound that is formed. The concepts of
take are defined in terms of its valency.
valencies and feature structures have been used to
introduced by French structuralist Lucien Tesniere
realize a chunker in the lines of the aforementioned
in dependency grammar formalism. Numerous the-
analogy. The following subsections examine the de-
oretical publications (Helbig, 1992; Welke, 1995)
velopment of this formalism in detail.
have established it as arguably the most widely
used model of complementation in languages like
units to its left and right that is represented
German, French, Romanian and Latin. Valency the-
through the corresponding bond energy. Sec-
oretic description of English has also been explored
tion 3.3 provides further discussion on the theo-
retical and practical issues concerning bond en-
valency theory has focused on the syntactic and se-
mantic valencies of verbs and occasionally of nouns.
Category is simply the POS category of the syn-
tactic unit that the FS allows in the concerned
A generalization of the valency theory has been
proposed in this work, where instead of onlynouns or verbs, each syntactic unit of a sentence
Attributes are the allowable attribute of the syntac-
at every level of analysis has a certain number of
tic category in the respective hand.
chunking, where only adjacent words or groups can
N ewCategory - At every step of the chunking pro-
be attached to form larger groups, the units (word
cess two feature structures unite to form a new
or word groups) have a maximum of two valencies
associated with them - the right and the left. The
right valency defines the capability of the unit to
N ewAttributes - Similarly, N ewAttributes are
form groups with the units that lie to its right in a
the attributes of the FS obtained through uni-
sentence. The left valency can be defined likewise.
However, the affinity of a unit to form groups also
The FS corresponding to all the POS categories
depends on the syntactic attributes of the adjacent
and their different attributes is designed manually
through linguistic analysis. However, in the pres-
group with an adjective to its left, but never with
ence of an annotated corpus, these templates can be
of the adjacent units are also important. We use
Bond Energy
feature structure (FS) to represent the syntacticaffinities of a syntactic unit in terms of the valencies
and bond energies. Successful unification between
[[kAT hera T ebilaT ira]NN [upara]P P I ]NN
adjacent FS implies formation of a valid group with
tion era, as in kAT hera, has an affinity or valency
process releases an energy equal to the bond energy
for a noun or noun group (NN) to its right. Simi-
associated with that particular valency.
larly, a noun in the oblique form like T ebilaT iracan form a NN chunk with a post-position like
The basic contents of the FS are shown in
upara to its right. Therefore, the sequence of words
kAT here T ebilera upara can have two possible
morphological attributes, the FS also contains
[kAT hera [T ebilaT ira [upara]P P I ]NN ]NN
(left) hand specifies the constraints on the units to
and the aforementioned one, out of which only the
the right (left) of an object that can be grouped
latter is syntactically valid. The concept of bond en-
with it. The constraints are specified as a list of
ergy helps us solve this particular problem. Suppose,
5-tuples <BondEnergy, Category, Attributes,
the bond energy between NN and PPI is smaller than
that between NN-possesive and NN. Then in our ap-
elements of the 5-tuples can be described as follows:
proach, the group between NN-pssesive and NN willform before NN and PPI, thus leading to the correctgrouping. Similarly, an adjective can connect to a
BondEnergy - The formalism assumes a variable
noun to its right and a qualifier to its left. However,
affinity for a particular syntactic unit towards
in a sentence, when an adjective is followed by a
Figure 2: Contents of a Feature Structure
noun and preceded by a qualifier, the correct group-
elements of BE. We are interested in a patial
ing requires adjective to be grouped with the quali-
ordering between the bond energies. Note that
fier first, and then the new adjectival group is joined
we need to compare BEij only with BEki, for
with the noun. This is illustrated by the chunk
all ks other than j, beacause an ambiguity oc-
curs only when a particular category can form
in example 3. Therefore, we can conclude that the
bonds with the units both to its right and left.
bond energy between qualifier and adjective is more
We call such elements as comparable pairs.
than the bond energy between an adjective and a
Thorough linguistic analysis has led us to 47
noun.Thus, bond energy helps us decide which way
unique values for the bond energies, based on which
the bond will form (or in other words, units will be
all possible ambiguous pairs can be compared. Note
grouped) whenever there are multiple possibilities.
that it is not important to know what are these 47 val-
Let there be N POS categories from C1 to CN .
ues, only the ordering is important. In other words,
Let Ci · lef tBE(Cj) be the bond energy between
these 47 distinct values have been chosen arbitrar-
Ci and Cj when Cj is to the left of Ci.
ily from the set of natural numbers. It should be
rightBE(Cj) can be defined likewise. We make
mentioned here that a given sentence can be inher-
ently ambiguous and lead to multiple valid group-
ings. Since, we do not preclude the use of the same
i · lef tBE(Cj ) is 0 if Ci cannot be grouped
bond energy value for a comparable pair, multiple
grouping emerge as a natural possibility. We illus-
• Ci · lef tBE(Cj) is equal to Cj · rightBE(Ci).
trate this with the following examples.
• We need to estimate only N ×N bond energies,
that can be stored in a matrix BE, such that
ij = Ci · lef tBE(Cj ) = Cj · rightBE(Ci)
• It is not necessary to assign exact values to the
1. The list of FSs is stored in an array F .
2. Initially, for every pair of FSs in the sentence,
the bond energy between them is calculated andstored in a max-heap B.
3. The arrays F and B are stored in a global stack
Thus, in order to retain the possibility of both the
groupings, we must assign the same bond energiesto the pairs NN-possesive and NN, and NN and VN
4. The stack is popped to get a partial grouped list
of FSs - denoted by B and F for this run. The Grouping Algorithm
5. The maximum bond energy bmax is extracted
from B and the two corresponding FSs x and y
The grouping algorithm of the formalism proceeds
by first instantiating the feature structures for eachand every word and the punctuation marks in a sen-
6. If only one such pair is present, then the bond
follows a divide and conquer approach that eases
the complexity of full parsing. The following sub-
of the hands of either x or y. Let the FS after
subsections concentrate on the details of the algo-
unification be z. z is inserted into the array F . Instantiation of Feature Structures
7. The BondEnergies between z and the FSs to
After an input sentence sentence is fed to the POS
its right and left which are denoted by bz
tagger, the sentence comes as input to the chunking
system with the POS tags and morphological
8. At step 5, if there are multiple values of b
attributes attached with each of the words and
for each of the values, Steps 6 and 7 are re-
sentinels. The tagged sentence is fed into the initial
instantiator. The steps of instantiation are:
stored in the global stack S. The control flowstarts from Step 5 again.
1. Each word of the sentence is extracted one after
tial grouped structure is stored in S and control
2. A rule file which assists in the process of in-
stantiation consists of the template of FS for
10. If at Step 5, the value of bmax is zero, the
a POS category and its attibutes. The present
system uses inflection as the only syntactic at-tribute for chunking purposes.
3. For each word, a new instance for the FS is cre-
Handling Conjunction
ated from the template, which is selected from
A thumbrule for handling conjunctions and other
the rule file based on the POS tag and the at-
conditionals is applied before storing the configu-
tribute information associated with the word.
ration B and F in the stack S in Step 11/12. The
The Grouping Process
After the instantiation of the feature structures of
1. For all the FSs in F , it is checked whether
each syntactic unit of the sentence, the grouping pro-
cess starts a greedy process and proceeds in the fol-
Attributesv>,<P OSw, Attributesw> exist
in the list of tuples stored in a file for handling
output from the chunker: hugalI/NN [nadIra [duitIre]/NN]/NN kolakAtA/NN [ga.De uTheChe.]/VF
2. For all such sets of 3 FSs, the 3 FSs are united
However, note that the correct grouping is [hugalI
to form a single FS x with new category P OSx
nadIra]/NN.poss [dui tIre]/NN]/NN [kolakAtA]/NN
and attributes Attributesx, both of which is
3. After unification, the new FS x is inserted into
Implementation and Results
the list F , and the bond energies of x withthe FSs to its right and left are inserted into B
A chunker for Bengali has been implemented based
maintaining the decreasing order of the array.
on the aforementioned framework. It depends on
An Example
a morphological analyzer (MA) and a POS tagger,both of which have been developed in-house and
Below we illustrate the process of chunking with an
have accuracies of 95% and 91% respectively. The
salient features of the chunker for Bengali are men-
Input sentence: hugalI nadIra dui tIre kolakAtA ga.De uTheChe. Hoogly river’s two bank Kolkata built up
• The chunker uses 39 tags and 47 distinct values
Kolkata has grown up on the either banks of river
Hoogly. After MA and POS-tagging and FS instantia-
• The chunks identified by the system are nested.
Their categories are noun-chunks (NN), finite
verb chunks (VF), non-finite verb chunks (VN),
adverbial chunks (ADV) and adjectival chunks
(JJ). The punctuation marks other than ”,” form
• The templates of the feature structures are spec-
ified manually in a rule file. There are 75 such
templates for the different POSs and their re-spective attributes. The process of bonding: There are two possible bonds that can be formed at the first step - that
• Multiple word groupings for the same sentence
between dui - tIre and ga.De - uTheChe.
former has the higher bond energy 2 and thereforeis chosen. The resulting category is an NN (noun
• The chunker cannot identify multiword ex-
pressions, named entities and clausal conjunc-
tions of conditional constructs .It cannot handle
nadIra [dui tIre]/NN kolakAtA ga.De
cases where semantic issues are involved.
Since, the accuracy of the chunker heavily de-
pends on the accuracies of the pre-processing steps
At this point again two bonds can form, both of
such as MA and POS tagging, evaluation of the
which have the same bond energy. Since the bonds
system as such will not reflect the accuracy of the
are non-overlapping, it does not matter which
chunking algorithm. Therefore, in order to estimate
one is chosen first. Finally, we get the following
the accuracy of the chunking algorithm rather than
2The meaning of the symbols are - NP: proper noun, poss:
the system as a whole, the present chunker has been
possesive, JQ: quantifying adjective, NN: noun, V: Verb, nf:
tested on a POS-annotated corpus of about 30,000
non-finite, f: finite, CAT: category, attr: attribute, be: bond en-ergy
words. The corpus has been developed in-house by
manually annotating a subset of the Bengali mono-
Acknowledgement
lingual corpus provided by CIIL. A few conven-tions have been kept in mind while evaluating the
This work has been partially supported by Media
accuracy of the algorithm. Since it produces word
groups which may be nested, the outermost chunkhave been considered during evaluation. Therefore,for a particular sentence, the chunker produces a
References
set of non-overlapping chunks which may have a
S. Abney. 1991 Parsing by Chunks. Principle Based
correct or an incorrect structure. The average pre-
Parsing. Kluwer Acedemic Publishers.
cision and recall rates are 96.12% and 98.03% re-
D. Allerton. 1982. Valency and the English Verb. Lon-
spectively. A cent percent accuracy in chunking is
not observed since the system cannot identify multi-
A. Bharati, V. Chaitanya, and R. Sangal. 1995. Natural
word expressions and named entities. Most of the
Language Processing: A Paninian Perspective. Pren-
incorrect chunks are due to the occurrences of these
two phenomena in natural language text.
S. Buchholz, J. Veenstra, and W. Daelemans. 1999. Cas-
caded Grammatical Relation Assignment. Proceed-Conclusion
In this paper, a framework has been described forchunking of free word order languages based on a
G. Helbig. 1992. Probleme der Valenzund Kasustheorie.
generalization of the valency theory implementedin form of feature structures.
T. Herbst. 1999. English Valency Structures - A first
strong analogy between formation of word groups
sketch. Technical report EESE 2/99.
and formation of larger chemical structures from
bond energy between syntactic units provided a lot
CoNLL-2000 and LLL-2000. Lisbon, Portugal, 2000.
of representational ease in capturing the problem of
L. A. Ramshaw, and M. P. Marcus. 1995. Text Chunk-
ing using Tansformation-Based Learning. ACL ThirdWorkshop on Very Large Corpora
The formalism can be extended to complete
P. R. Ray, Harish, V., S. Sarkar, and A. Basu 2003 Part of
parsing of free word order languages. This can be
Speech Tagging and Local Word Grouping Techniques
accomplished through the inclusion of semantic
for Natural Language Parsing in Hindi. Proceedings of
valencies and non-adjacent syntactic valencies,
International Conference on Natural Language Pro-cessing (ICON 2003). Mysore, India.
which will be associated with a non-adjacent bondenergy value. The idea is similar to that of karaka or
M. Vilain, and D. Day 2000. Phrase Parsing with Rule
traditional valencies of verbs. Also, the system can
Sequence Processors: an Application to the SharedCoNLL Task. Proceedings of CoNLL-2000 and LLL-
be extended by starting to chunk the words without
the intervention of the POS tagger. An untaggedsentence may serve as the input of the chunker
K. Welke. 1995. Dependenz, Valenz und Konstituenz.
and the system may tag and chunk in one go to
Ludwig M. Eichinger and Hans-Werner Eroms (eds.). Dependenz und Valenz.
make the chunker independent of the POS tagger.
A morphological analyzer would serve as the frontend to such a system. If semantic resources become
T. Zhang, F. Damerau, and D. Johnson.
Chunking based on a Generalization of Winnow. Jour-
available for Bengali and other free word order
nal of Machine Learning Research, 2 (March).
languages, then the present system can be extendedto a full parser for such languages.
Affordable Health Care—in a Book Publishers keep up with the burgeoning of new ap- Craig Panner, editorial director of the med- proaches to health care and the need for fresh infor- ical division at Oxford University Press, says, mation “As we begin to prepare for the AffordableCare Act, publishers recognize the importanceof, and the need for, high-quality consumer ed-ucation mater
The purpose of this organization, operating under the auspices of the Houston Symphony society, is to promote quality music education and enrichment programs for area students and to promote music appreciation in the Bay Area through an affiliation with the Houston Symphony and other resources. APOLLO CHAMBER PLAYERS BAHSL’s September meeting program will feature the Apollo Chambe
 and verb phrases is neither simple nor efficient.
and verb phrases is neither simple nor efficient.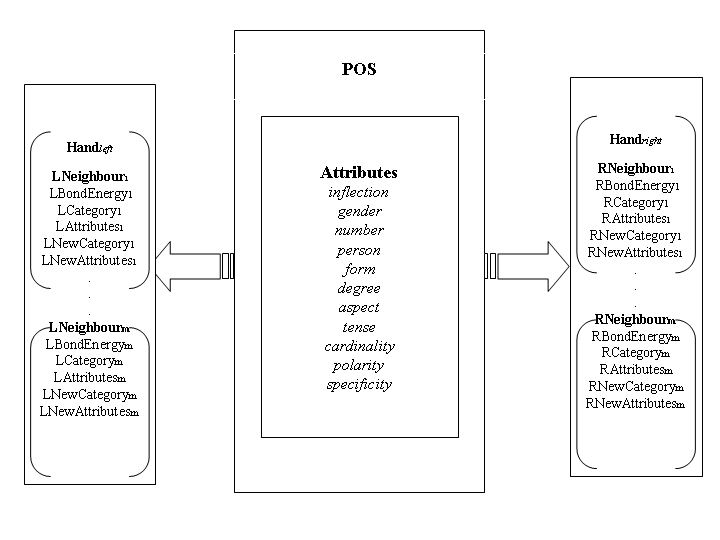 Figure 2: Contents of a Feature Structure
noun and preceded by a qualifier, the correct group-
elements of BE. We are interested in a patial
ing requires adjective to be grouped with the quali-
ordering between the bond energies. Note that
fier first, and then the new adjectival group is joined
we need to compare BEij only with BEki, for
with the noun. This is illustrated by the chunk
all ks other than j, beacause an ambiguity oc-
curs only when a particular category can form
in example 3. Therefore, we can conclude that the
bonds with the units both to its right and left.
Figure 2: Contents of a Feature Structure
noun and preceded by a qualifier, the correct group-
elements of BE. We are interested in a patial
ing requires adjective to be grouped with the quali-
ordering between the bond energies. Note that
fier first, and then the new adjectival group is joined
we need to compare BEij only with BEki, for
with the noun. This is illustrated by the chunk
all ks other than j, beacause an ambiguity oc-
curs only when a particular category can form
in example 3. Therefore, we can conclude that the
bonds with the units both to its right and left.